
Uses of Automated Feature Engineering for Predictive Modelling
Introduction
I am an intern learning about generating predictive models. Manual feature engineering is a critical part of the model building process. With the advent of automated feature engineering by Featuretools, an open source python framework, manual processes can be minimized, allowing for a combination of manual and automated features to maximize the efficiency and accuracy of a model.
The idea for this project is to leverage the automated feature engineering functionality of Featuretools with a specific use case to learn more about the generated features and their importance to model building. The use case is for a restaurant aggregator site like Yelp, which has clients who pay to have their restaurant featured. Through the site, consumers are able to book reservations and place various filters on restaurants they are searching for, such as area and cuisine.
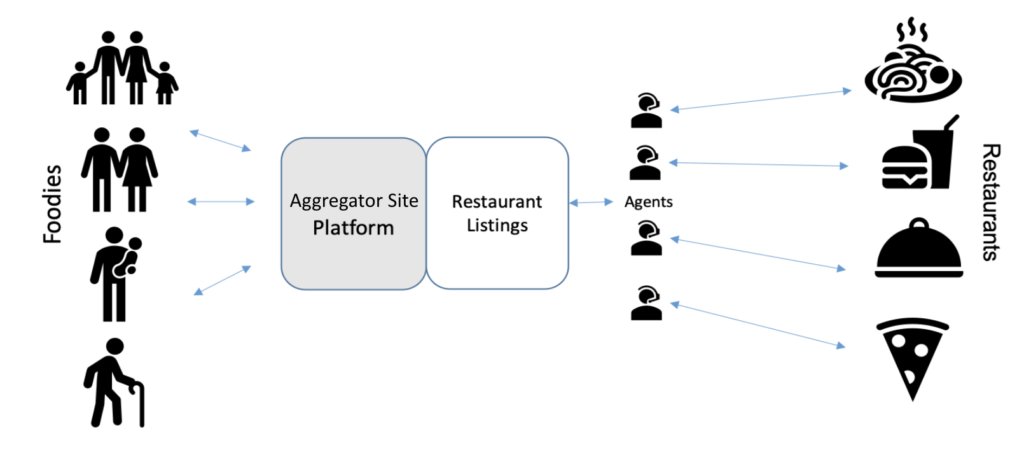
The use case is to help the aggregator site to make sure restaurants do not churn. The goal of the model is to predict which clients are likely to leave. Knowing early can help the aggregator site be proactive in preventing churn.
Goals of the project
Objectives include 1) using Featuretools to observe what kind of features are automatically generated based on our data and 2) ascertaining how significant the generated features are respective to our use case model.
Aspects of this project include creating unique indices for datasets, creating entity sets containing multiple datasets, and defining the relationship between those datasets. The next step requires deep synthesis learning with Featuretools to automate features that are added to our primary dataset. Production and analyses of multiple models simulated from different versions of this data (combination of manual and automated features, only manual features, and only automated features) will help determine the use of Featuretools and its implications for future modelling.
Data Variables
Client Data
- Agent ID: The ID of the agent assigned to the restaurant
- Client ID: the ID number of a specific restaurant
- Client Join Date: the date the restaurant was added to the aggregator site
- Client Left Date: if applicable, the date the restaurant left the aggregator site
- Total number of seats: Maximum occupancy of the restaurant
- Internet reservation: whether a user of the site can make an online reservation for a restaurant [yes/no]
- Service Level: subscription level of client
Call Data
- Client ID: the ID number of a specific restaurant
- Date: the date and time of the call from an agent to that restaurant
- Agent_ID: the ID of the agent who called the restaurant
- Notes: content of the call
Data Manipulation
Before using Featuretools to perform automated feature engineering, data manipulation of client and call data was required. Using pandas in a Jupyter notebook allowed for standard operations such as loading client and call datasets, dropping columns, and adding a churn flag column.
|
#Read in the data client_cleaned = pd.read_csv(‘client.csv’, parse_dates = [‘Date_Added_as_Client’]) calls_cleaned = pd.read_csv(‘result.csv’, parse_dates = [‘CallDate’]) |
|
#Cleaning up data and removing Japanese character fields clients = client_cleaned.drop(columns=[‘Store_Name’,’Location’, ‘Documents_for_Leaving’, ‘Documents_for_Leaving_Memo’, ‘Genre_of_Food’, ‘Average_customer_transaction’, ‘Search_budget’, ‘Regular_Holiday’, ‘Service_Area’, ‘Middle_Service_Area’, ‘Area’]) |
|
calls = calls_cleaned.drop (columns=[‘ClientTalker’,’Dialogue_channel’, ‘Reason_For_Call’,’CallResult’]) |
|
#Creating a churn flag column for the client data def is_nan(x): return isinstance(x, float) and math.isnan(x) def churn(data): if not is_nan(data): return 1 else: return 0 clients[‘churn_flag’] = clients[‘Date_Left’].apply(churn) |
One manipulation required to use Featuretools was having one column in our “parent” table which had unique values for each row. Due to the fact that our client data did not have such a column (Client ID’s were repeated, as the data was collected from a period of 14 months), a manipulation was performed to create a new column which was a combination of the Client ID and the month it was collected from, called “client/month”. This column was added to both the client data and the call data, so the data could be linked to each other via that column later.
How Featuretools Is Used
After the data was transformed, it was compatible to interact with Featuretools. The first step was creating a new EntitySet in which client and call data was added.
|
# Creating a new EntitySet es = ft.EntitySet(id = ‘clients’) |
|
#Creating entities to put into the EntitySet es = es.entity_from_dataframe(entity_id = ‘clients’, dataframe = clients, variable_types = {‘year_month’: ft.variable_types.Categorical, ‘churn_flag’: ft.variable_types.Categorical}, index = ‘client/month’, time_index = ‘Date_Added_as_Client’) |
|
es = es.entity_from_dataframe(entity_id = ‘calls’, dataframe = calls, variable_types = {‘Business period’ : ft.variable_types.Categorical, ‘year_month’ : ft.variable_types.Categorical}, make_index = True, index = ‘call_id’, time_index = ‘CallDate’) |
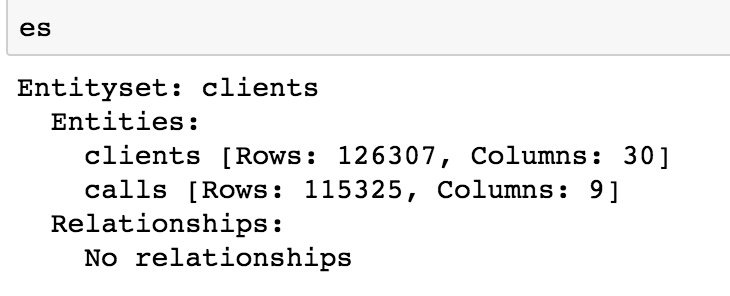
An optional field to infer the variable types in this table is called variable_types. If no value is entered, Featuretools automatically infers type for each variable. Some categorical variables had been categorized as numerical, such as year_month, churn_flag, and business_period. Using ft.variable_types.[Variable_Type], these variables were changed to be categorical. Running [es] shows both datasets added to the EntitySet.
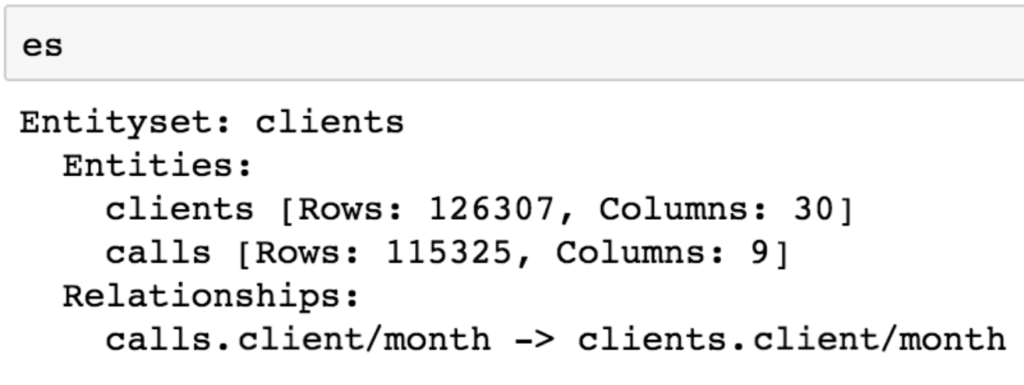
The next step is defining the relationship between the two datasets, related in this case by the column field “client/month”. Using the ft.Relationships functionality of Featuretools, parent client data related to child call data by their common column, “client/month”. This relationship was then added to the EntitySet, which can be seen by running [es] again.
|
# Relationship between call data and client data client_call_relationship = ft.Relationship(es[‘clients’][‘client/month’], es[‘calls’][‘client/month’]) # Add the relationship to the entity set es = es.add_relationship(client_call_relationship) |
After the relationship is defined, Featuretools allows us to perform automated deep feature synthesis on the data.
|
# Perform deep feature synthesis without specifying primitives feature_matrix, features_list = ft.dfs(entityset=es, target_entity= ‘clients’, chunk_size=0.01) |
Aggregation and transformation functions as well as combination of two functions (called a feature with a depth of 2) were applied onto variables in the existing data and subsequently added to the existing dataset. A list of the features added to our original dataset is shown below.
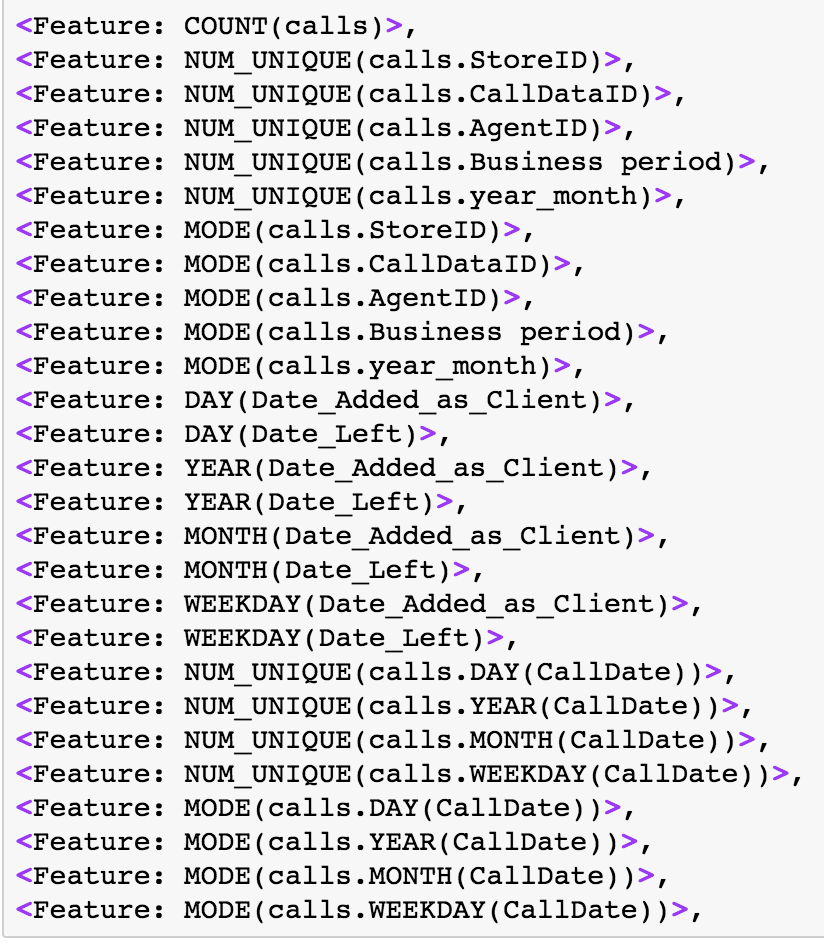
After these features were added, their utility could be evaluated in model building using ScoreFast (™).
Downsampling Data Before Modelling
Looking at the distribution of the data after uploading it onto the ScoreFast(™) platform proved useful, as it showed that the churn_flag data was skewed, with 90.22% of the data having a churn_flag value of 0. This unbalanced class distribution caused the first round of modelling to have disproportionately high error in categorizing the churn_flag as 1. Therefore, downsampling data to have a 2:1 class0:class1 ratio helped to balance the dataset.
|
count0,count1 = dataset.churn_flag.value_counts() dataset_class0 = dataset[dataset[‘churn_flag’]==0] dataset_class1 = dataset[dataset[‘churn_flag’]==1] dataset_class_0_under_2 = dataset_class0.sample(2*count1) dataset_test_under = pd.concat([dataset_class_0_under_2, dataset_class1], axis=0) |
Code for downsampling the audited data
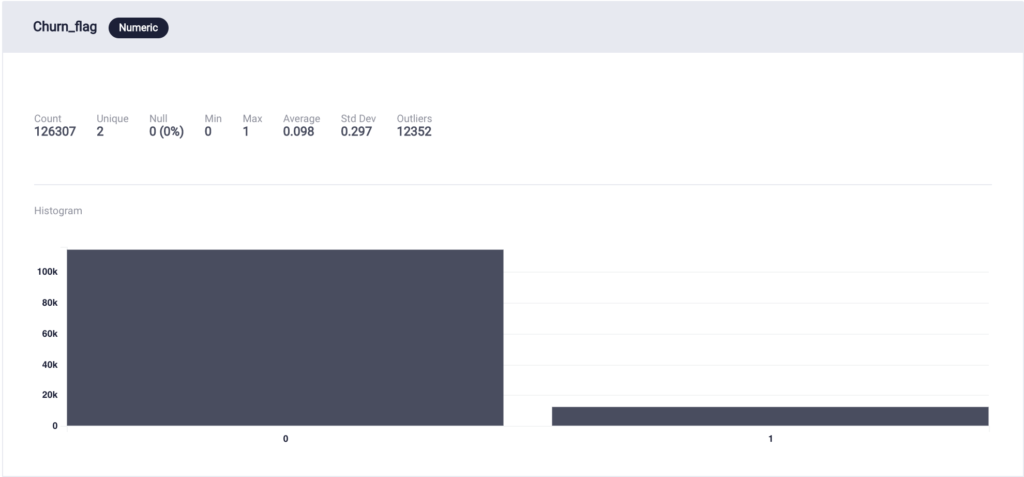
Distribution of the data before downsampling
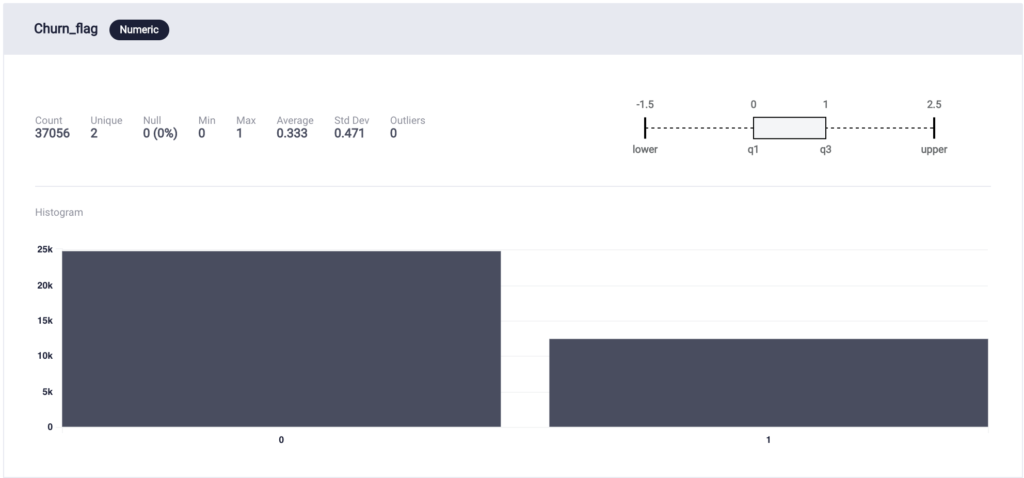
Distribution of the data after downsampling
Modelling Phase
Using ScoreFast (™), this project culminates in evaluating the importance of the features added to our data in order to create a machine learning model that effectively predicts client churn. Model testing was performed on the combined dataset including manual and automated features (M1), the original dataset that included only manually engineered features (M2), and a third dataset that contained only the automated features generated by Featuretools (M3).
From the results of the modelling phase, the algorithm with the best precision and recall across both models was the XGBOOST algorithm, so it was chosen for prediction. When compared, M1 (manual and automated features) has the best accuracy, AUC, precision, and recall.
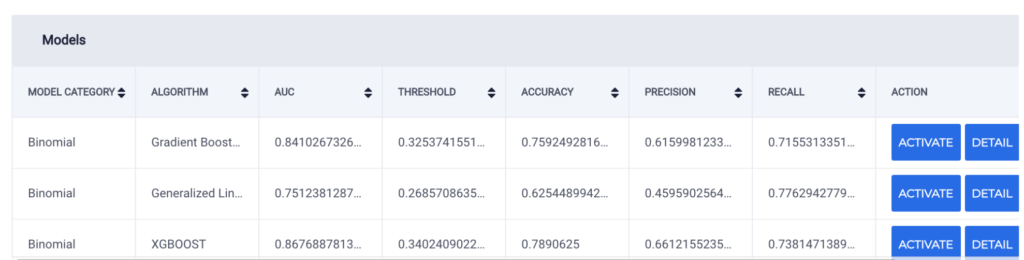
M1 Model Overview
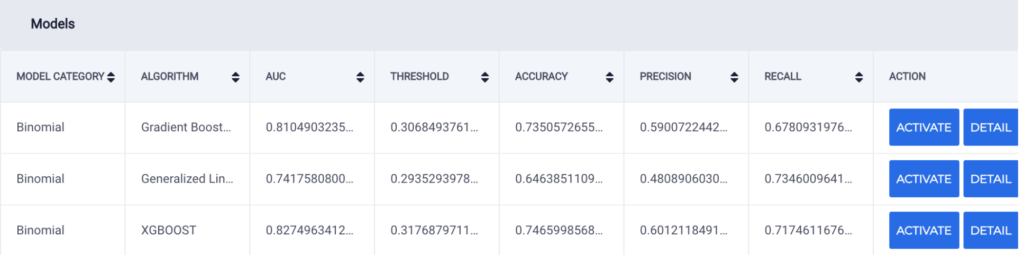
M2 Model Overview
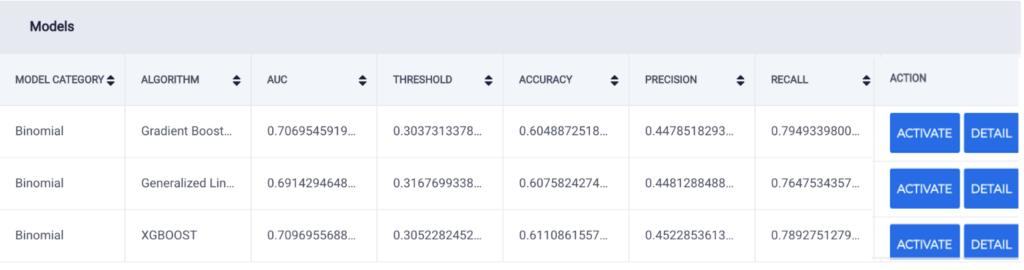
M3 Model Overview
The variable importances of the features for each model are shown below.
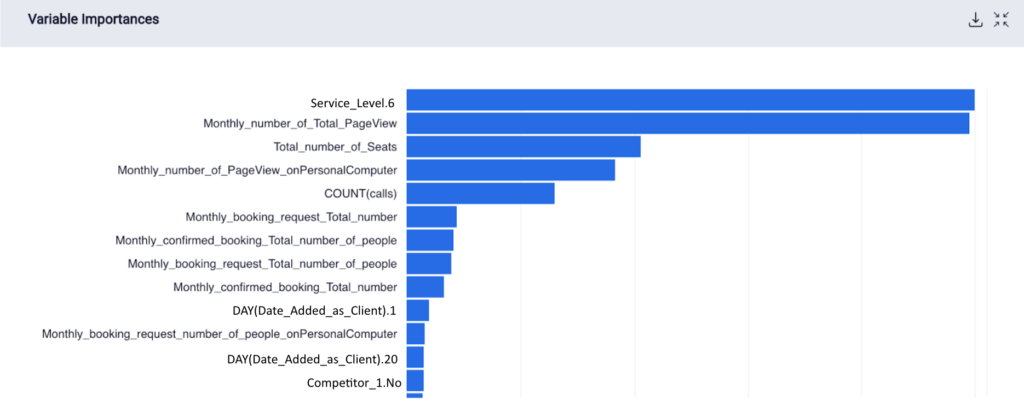
Variable Importances for M1
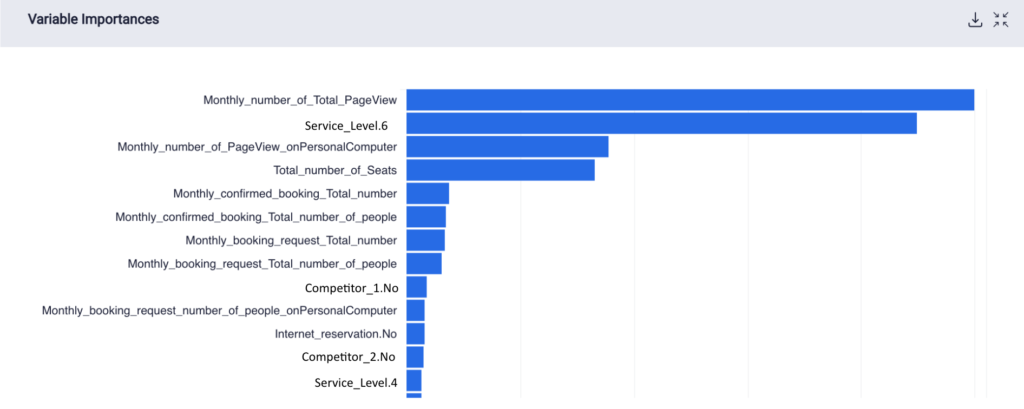
Variable Importances for M2
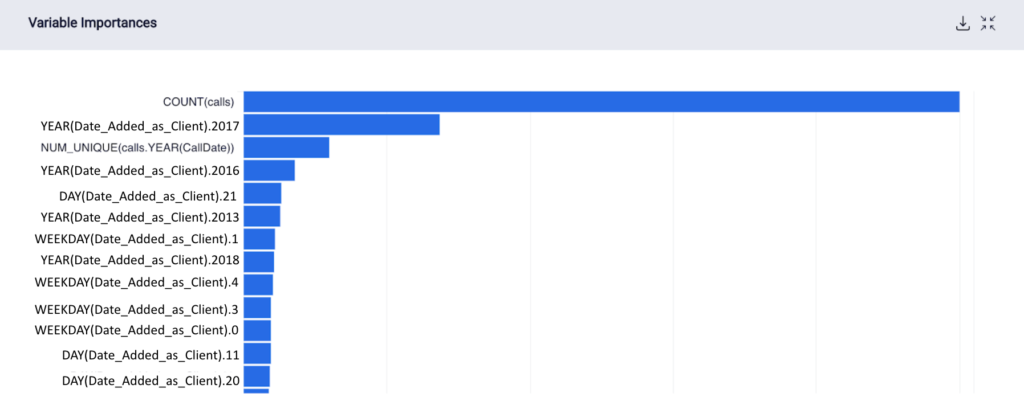
Variable Importances for M3
Most of the statistically significant variables are manually engineered features, with certain automated features providing useful information to train the model, such as the count of calls and the day the client was added. In M3 this is emphasized again, because without manual features, the count of the calls for that month, the year the restaurant was added as a client, and how many times a year they were contacted proved critical to the model.
Prediction Results
On ScoreFast(™), we have the option of scoring a percentage of our data, or scoring individual rows of the data to see the model’s confidence in predicting the response variable, in this case the churn_flag. Scoring individual rows can give an idea of how confident the model predicts a churn_flag of 0 or 1 compared to the actual value.
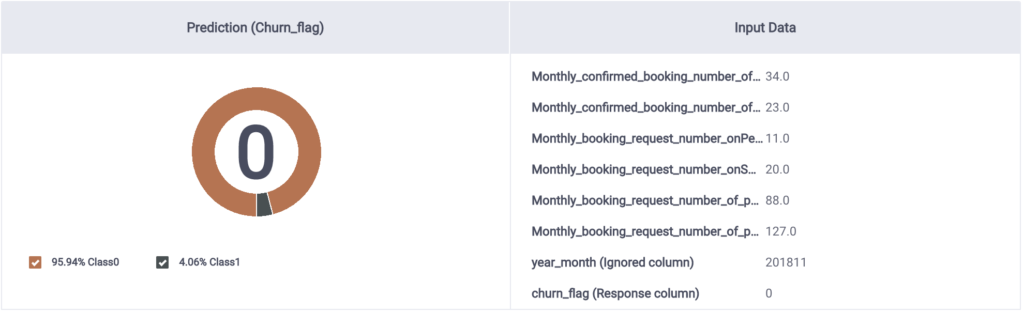
M1 Prediction Value
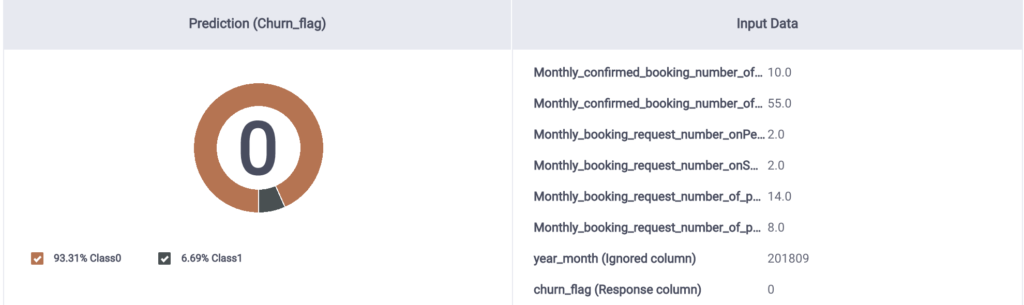
M2 Prediction Value
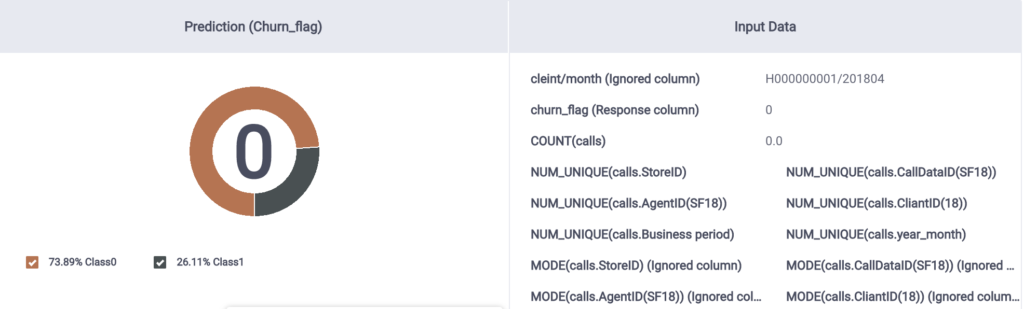
M3 Prediction Value
All models predicted the accurate churn_flag value of 0 with fairly high accuracy, with M1 having slightly better confidence than M2, and M3 having fairly less confidence in the prediction.
Conclusions and Remarks
From going through data manipulation, Featuretools deep learning, modelling and prediction, I have learned the importance of finding efficient ways to make feature engineering as efficient as possible. In this use case, Featuretools was great for helping with stacking features on top of each other for numerical data; however, a majority of the data from this use case was categorical, which did not always mesh well with Featuretools aggregation functions.
Featuretools is a great way to start the feature engineering process or add auxiliary aggregation features after manually engineering other features. I look forward to exploring how it can be used with more numerical data and other projects in the future.
python
#Read in the data
client_cleaned = pd.read_csv(‘client.csv’, parse_dates = [‘Date_Added_as_Client’])
calls_cleaned = pd.read_csv(‘result.csv’, parse_dates = [‘CallDate’])